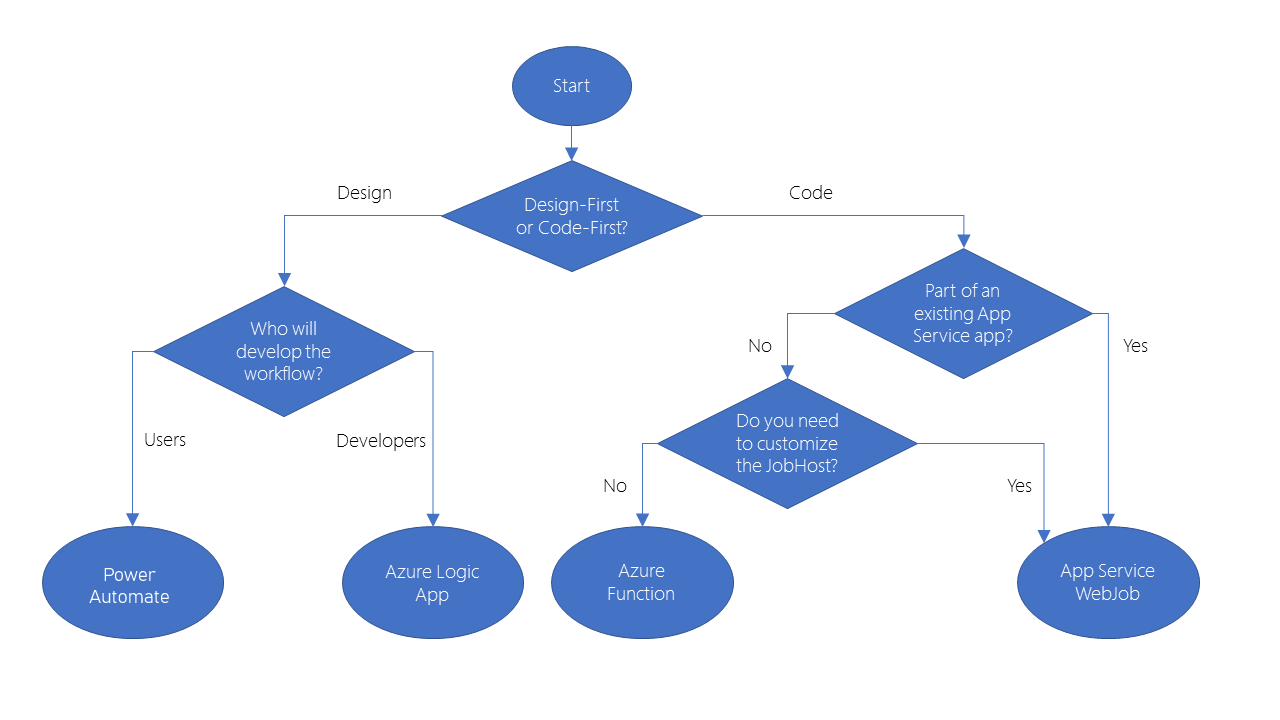
The onboarding posts go through the important points, that an Azure Cloud Solution Architect has to know to get started for certificate preparation. The prepration for the certificate has the following steps:
- Get familier with Azure services
- Know the keywords
- Get familier with the key concept of each Azure service
- Know how to use them in practice
- Know the Cloud Architecture Design Patterns
Topices
Keywords
- Serverless
- Azure Function
- Logic App
- Azure queue technologies
- Azure queue storage
- Azure Service bus queue
- Azure service bus topic
- Azure event technologies
- Event grid
- Event hub
- Notification Hub
Serverless logic with Azure function
Scenario: Imagine you work for an escalator company that has invested in IoT technology to monitor its product in the field. You oversee the processing of temperature sensor data from the drive gears of the escalators. You monitor the temperature data and add a data flag to indicate when the gears are too hot. In downstream systems, this data helps determine when maintenance is required.
Your company receives sensor data from several locations and from different escalator models. The data arrives in different formats, including batch file uploads, scheduled database pulls, messages on a queue, and incoming data from an event hub. You want to develop a reusable service that can process your temperature data from all these sources. [Source]
Azure function has three components like all the function that we develop:
- Input/s: which is done by a json configuration without developing a code.
- Logic: the part that you have to develop with the language you like.
- Output/s: which is done by a json configuration without developing a code.

- Azure function
- Can be considered as the Function as a Service (FaaS)
- Function can be a microservice (But don’t user Azure Function for long run workloads)
- Auto scale infrastructure (scale out or down) based on load
- Automatic provisioning by cloud provider
- Use the language of your choice.
- Less administrative tasks and more focus business logic
- Important characteristics of serverless solutions
- Avoid over-allocation of infrastructure (you pay only when the function is running)
- Stateless logic (as the work around the states can be stored in associated storage services)
- Event driven (they run only in response to an event e.g. receive an HTTP request, message being added to a queue,… No need to develop a code for listening or watching the queue). Refer to Azure function triggers to see a list of supported services.
- Drawbacks of serverless solutions
- Execution time: Function has a timeout of 5 minutes and configurable to 10 minutes. With Azure Durable Functions we can solve the timeout problem.
- Execution frequency: if the function is used/ executed continuously, it’s prudent to host this service on a VM unless it will get expensive/costly.
- Function APP
- It’s for logically group the functions and resources.
- Service Plan ( Azure function is a serverless service but doesn’t mean, that it doesn’t have a server, where it have to be hosted and run. Azure function has a server, where it’s hosted and run but Cloud provider will provision the resources for you)
- Service Plan Types
- Consumption Service Plan
- Timeout 5-10 min
- Automatic scaling
- Bills you when function is running
- App Service Plan (Not serverless anymore)
- Avoid timeout periods + continuously run
- Consumption Service Plan
- Azure function uses a storage account as well for logging function execution
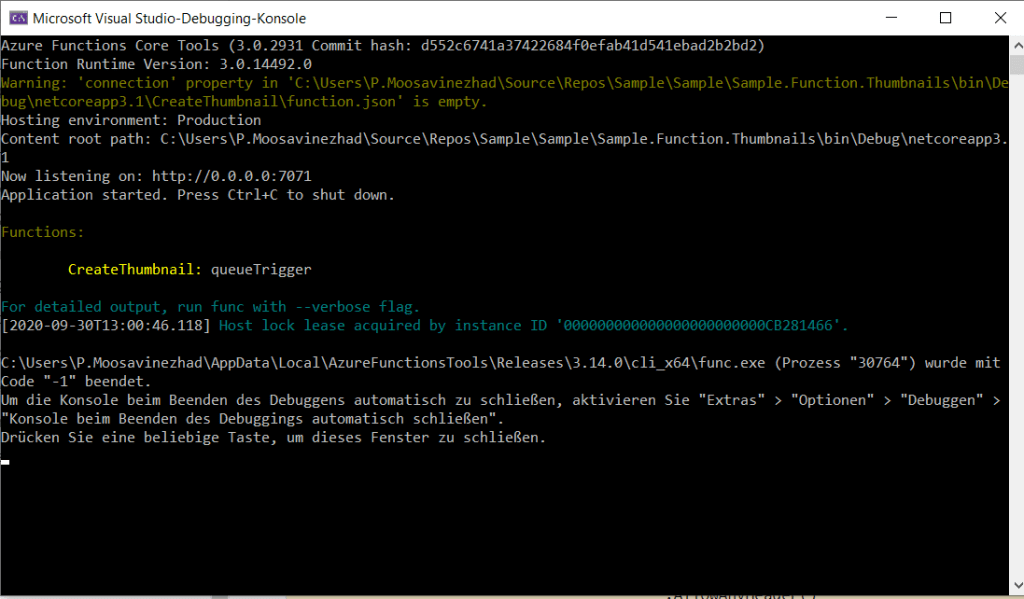
- Azure function can be tested as well, refer to screenshot below. To have automated test use the deployment slots and deployment center. They are explained in next sections.
- Use the Monitor option in the screenshot below to check the executions.
Azure function triggers
Blob storage
Microsoft graph events
Azure cosmos db
Queue storage
Evnt grid
Service bus
Http
Timer
Azure function binding
Azure function has to have input and output bindings.
{
"bindings": [
{
"name": "order",
"type": "queueTrigger",
"direction": "in",
"queueName": "myqueue-items",
"connection": "MY_STORAGE_ACCT_APP_SETTING"
},
{
"name": "$return",
"type": "table",
"direction": "out",
"tableName": "outTable",
"connection": "MY_TABLE_STORAGE_ACCT_APP_SETTING"
}
]
}
- Binding is a declarative way to connect data to your function.
- Bilndings contains (Azure Doc)
- input/s
- output/s
Scenario: Let’s say we want to write a new row to Azure Table storage whenever a new message appears in Azure Queue storage. This scenario can be implemented using an Azure Queue storage trigger and an Azure Table storage output binding.
Each function contains
- function.json -> bindings are configured here
- run.csx -> logic is developed here

This sample code is a microservice architecture with “database per service” design pattern. When a new product is added, a message is pushed to the storage queue for each image of the product. By pushing the message/s to the queue, the function is getting run, gets the original image/s from a storage container, generates the thumbnail and saves it to another container.
By Creating a function app some resources are creating by default.

The following figures demonstrate testing an azure function.

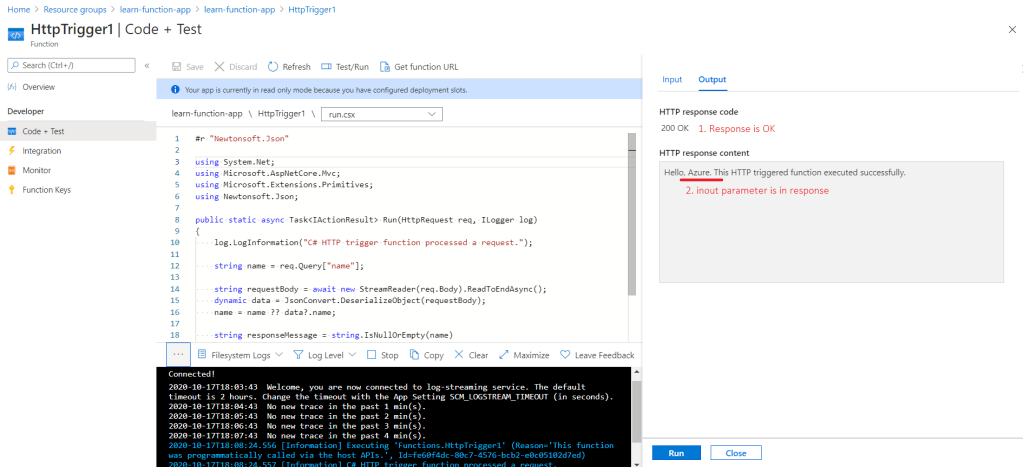
Monitor the execution
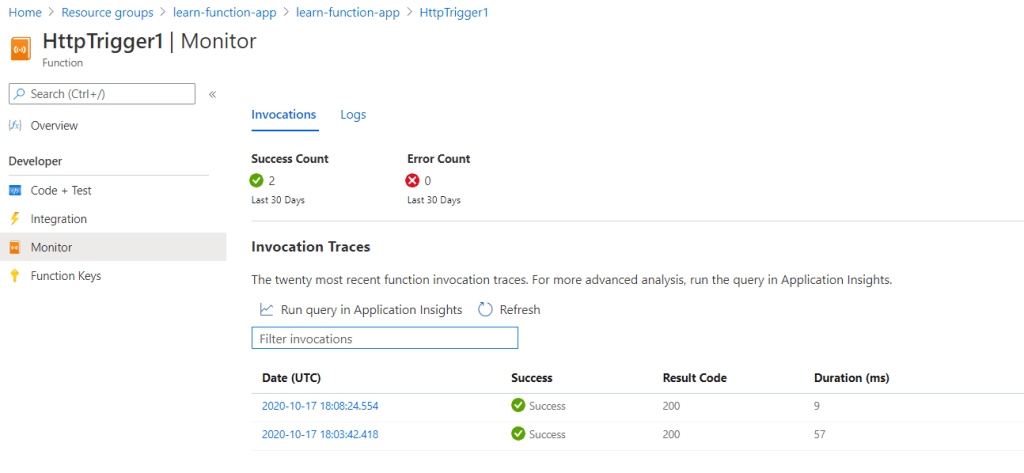
Secure the azure function backend
- User API Key to block unknown callers.
- To use this feature the function must have
Source
Route and Processing via Logic App
Scenario: For example, in the shoe-company scenario we want to monitor social media reaction to our new product. We’ll build a logic app to integrate Twitter, Azure Cognitive Services, SQL Server, and Outlook email.
- Azure Logic Apps
- Make diverse services work together
- Provide pre-built components that can connect to hundreds of services
- Steps of designing a logic app
- Plan the business process (step based)
- Identify the type of each step
- Logic apps operations
- Trigger -> respond to external events. Triggers are for lunching the logic app.
- Action -> process or store data
- Control action -> make decision based on data
Example:
- detect tweets about the product -> Trigger
- analyze the sentiment -> Action
- If logic -> Control
- store a link to positive tweets -> Action
- email customer service for negative tweets -> Action


An external service must have a connector to be usable in logic app.
The left figure illustrates the twitter connector. A group of related triggers and actions are packaged inside a connector
Trigger types

Polling trigger: periodically checks an external service for new data e.g. check RSS feed for new posts. For polling trigger we have to set frequency (second, minute, hour) & interval e.g. frequency = minutes & interval = 5 means the pooling trigger runs each 5 minutes.
Polling triggers force you to make a choice between how much they cost and how quickly they respond to new data. There is often a delay between when new data becomes available and when it is detected by the app. The following illustration shows the issue.
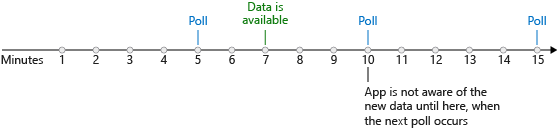
In the worst case, the potential delay for detecting new data is equal to the polling interval. So why not use a smaller interval? To check for new data, the Logic Apps execution engine needs to run your app, which means you incur a cost. In general, the shorter the interval, the higher the cost but the quicker you respond to new data. The best polling interval for your logic app depends on your business process and its tolerance for delay.
Polling triggers are perfect for the “route and process data” scenarios.
- Push trigger
- notifies immediately when data is available e.g. the trigger that detects when a message is added to an Azure Service Bus queue is a push trigger.
- Push triggers are implemented using webhooks.
- The Logic Apps infrastructure generates a callback URL for you and registers it with the external service by first creation and each later updates
- Logic Apps de-registers the callback for you as needed e.g. if you disable or delete your app.
- The nice thing about push triggers is that they don’t incur any costs polling for data when none is available
- If push triggers respond more quickly and cost less than polling triggers, then why not use them all the time? The reason is that not every connector offers a push trigger.
- Sometimes the trigger author chose not to implement push and sometimes the external service didn’t support push

Scenarios for the logic app
| When a message is received in a Service Bus Queue | When a HTTP request is received |
| When a new tweet is posted | When a Event Grid resource event occures |
| Recurrence | When a new email is received in Outlook |
| When a new file created in OneDrive | When a file is added to FTP server |
Source
Azure messaging model to loosely connect services
When a solution consists of several different services/programs, this solution is a distributed solution. In distributed solutions the components have to communicate with each other via messages.
Even on the same server or in the same data center, loosely coupled architectures require mechanisms for components to communicate. Reliable messaging is often a critical problem.
As the cloud solution architect you have to
- understand each individual communication that the components of the application exchange
- understand whether the communication sends message or event
- then you can decide to choose an event-based or message-based architecture
- Each communication can use different technologies
In the both event-based and message-based, there’s a sender and receiver. But the difference is the content of what they send.
Message
- Contains raw data
- This data is produced by sender
- This data is consumed by receiver
- It contains data/payload itself not just the reference to that data
- Sender expect that the destination component process this data in a certain way
E.g. mobile app expect that the web API save the sent data to a storage.
Available technologies
- Azure Queue Storage
- Azure Service Bus
- Message Queue
- Topics
Event
- Light weight notification that indicates something has happend
- Doesn’t contain raw data
- May reference where the data lives
- Sender has no expectations of receiver
E.g. Web API inform the Web App or mobile App about a new file.
Available technologies
- Azure Event Grid
- Azure Event Hubs
Azure queue technologies
The section explains more about Azure Queue Storage, Azure Service Bus Queue, and Azure Service Bus Topic and when which technology can be used in the solution.
- Azure queue storage
- This service is integrated in Azure storage account
- Can contains millions of messages
- The queue limitation is by the capacity of the storage account
- Azure service bus queue
- It’s a message broker system intended for enterprise applications
- For higher security requirements
- have different data contracts
- utilize multiple communication protocols
- include both cloud and on-prem services
In message queues of the Azure queue storage and the Azure service bus queu, each queue has a sender and a subscriber. Subscriber takes the message and process is as the sender expects.
Both of these services are based on the idea of a “queue” which holds sent messages until the target is ready to receive them.
- Azure service bus topics
- It’s like queues
- Can have multiple subscriber
- Each subscriber receives its own copy of the message
- Topics use queues
- By post to a topic, the message is copied and dropped into the queue for each subscription.
- The queue means that the message copy will stay around to be processed by each subscription branch even if the component processing that subscription is too busy to keep up.
- Benefits of quese
- Increased reliability
- For exchanging messages (at times of high demand, messages can simply wait until a destination component is ready to process them)
- Message delivery guarantees
- There are different message delivery garanties
- At-Least-Once delivery
- each message is guaranteed to be delivered to at least one of the components that retrieve messages from the queue
- Example: in certain circumstances, it is possible that the same message may be delivered more than once. For example, if there are two instances of a web app retrieving messages from a queue, ordinarily each message goes to only one of those instances. However, if one instance takes a long time to process the message, and a time-out expires, the message may be sent to the other instance as well. Your web app code should be designed with this possibility in mind.
- At-Most-Once delivery
- each message is not guaranteed to be delivered, and there is a very small chance that it may not arrive.
- unlike At-Least-Once delivery, there is no chance that the message will be delivered twice. This is sometimes referred to as “automatic duplicate detection”.
- First-In-First-Out (FIFo) delivery
- If your distributed application requires that messages are processed in precisely the correct order, you must choose a queue system that includes a FIFO guarantee.
- At-Least-Once delivery
- There are different message delivery garanties
- Transactional support
- It’s useful for e.g. e-commerce systems. By clicking the buy button, a series of messages are sending off to different destinations e.g. order details system, total sum and payment details system, generate invoice system. If the credit card details message delivery fails, then so will the order details message.
- Increased reliability
How to decide for a queue technique
Queue Storage
- Need audit trail of all messages
- Queue exceed 80 GB
- Track processing progress inside queue
- It’s for simple solutions
Service bus queue
- Need At-Most-Once delivery
- Need FIFO guarantee
- Need group messages into transactions
- Want to receive messages without polling queue
- Need Role-based access model to the queue
- Need to handle messages larger than 64K but less than 256 KB
- Queue Size not grow larger than 80 GB
- Need batches of messages
Service bus topic
- If you need multiple reciever to handle each message
Azure event technologies
Scenario: Suppose you have a music-sharing application with a Web API that runs in Azure. When a user uploads a new song, you need to notify all the mobile apps installed on user devices around the world who are interested in that genre [Source]. The Event Grid is the pefect solution for this scenario.
- Many applications use the publish-subscribe model to notify distributed components that something happend.
Event grid
- It’s a one-to-many relationship
- Fully-managed event routing service running on top of Azure Service Fabric.
- Event Grid distributes events from different sources,
- such as Azure Blob storage accounts
- Azure Media Services
- to different handlers,
- such as Azure Functions
- or Webhooks
- to build event-based and serverless applications
- supports most Azure services as a publisher or subscriber
- can be used with third-party services
- provides a dynamically scalable, low-cost, messaging system that allows publishers to notify subscribers about a status change
Event hub

Source
Notification Hub
It’s a multi-platform, scalable push engine to quickly send millions of messages to applications running on various type of registered devices.
PNS: Platform Notification System
To push notification on multiple platforms
Success is achieved by perseverance and motivation.
Parisa Moosavinezhad