

Topics
Business Objectives define how the business can market and sell its products and services. It is crucial for all parts of the business to agree and strive for the same business objectives in order to smoothly operate the business and work with customers.
Key concepts
- Uptime:
- Downtime
- Recovery Time Objective (RTO): maximum amount of time that your service would be down.
- Recovery Point Objective (RPO): maximum amount of time over which you would lose data.
- Disaster Recovery: Bringing our system (major service) in another place in case of complete region outage.
They are the commitment that we do with customers
Big picture
Business objectives are where the other business functions of your company meet with the Engineering function. These other areas of the company focus on signing customers, managing finances, supporting customers, advertising your products, etc. Where all of these teams meet is in the realm of contracts, commitments and uptime. This is where other parts of a business have to collaborate with Engineering in order to come up with common goals and common language.

Developing your intuition
- Develop regular communication: when working across departments within your business, it’s important to communicate regularly and clearly.
- Be on the same page: using the same language is a good way to make sure that all teams are on the same page.
- Push back where necessary: It’s imprerative to be well-prepared when dealing with business objectives. Other business units might wish to make more aggressive commitments to close more sales. Be cautious and transparent. Make sure that business understands what meeting higher commitments will cost in term of both time and dollers.
- Be Prepared: Service disruptions can be rare enough that how to recover can be forgotten and can be tricky. Practicing recovery operations in key to doing them well. Which in turn is key to keep relationship and solid footing with your peers in other parts of the business.
It is important to gauge how much effort and cost will be involved in meeting different business objectives. Communicating these numbers will help keep the whole company centered around common and achievable goals. Setting unrealistic or unachievable goals can quickly lead to poor morale and missed deadlines. Before committing to a business objective, ensure that you have an idea of how to build, run, monitor and maintain a system that can achieve the desired metrics, and make sure that the rest of the business understands the resource that will be required to do so. In this fashion, it is key to get all parts of the company to work together to set these goals. These goals are so critical to success and potentially costly to achieve that they often must be set at the highest levels of the company.

Uptime
- Percentage of time: the percentage of time that a service is available. 99,9% is a standard uptime by many service level agreements. This percentage is measured over the course of a month.
- Part of every Service Level Agreement: if you likely face penalties for the SLA, it comes usually in the form of monetary or service credit that you would owe your customers.
- Requires diligence: you need to tack your platform uptimes to demonstrate to your customers that you are measuring it and meeting commitments.
In order to maintain a high level of uptime, we must have redundancy throughout the services.
Everything must be redundant:
– Databases
– Networking
– Servers
– Staff
Uptime is a measure of how much time an application or service is available and running normally. Uptime is often measured as a percentage, usually in the “number of 9s” vernacular. For example, “4 9s” refers to a service being available for 99.99% of a time period.
Services that offer Service Level Agreements (SLAs) typically start at 99% and get more stringent from there. 99.9% is a common SLA. The more “9s” an SLA offers, the more difficult and costly it is to achieve. You must ask yourself how much effort you are willing to put in and how much your company is willing to pay before proceeding into the territory of 4 9s or beyond.
Chart of number of nines
Uptime calculation
Allowed downtime is calculated on monthly bases because some months have different length.
Allowed downtime = (30 days 24 hours 60 minutes) – (30 days 24 hours 60 minutes * SLA percentage)
For example a 99% = 7.3 hours of allowed downrime per month



Drafting a Service Level Agreement (SLA)
When drafting a Service Level Agreement (SLA) for your platform, there are many things to consider. You will need to ponder what you will need to implement in order to meet the SLA, and also understand what types of guarantees that you are providing to your customers that you will meet the SLA. Monetary compensation is common for SLA violations either in the form of service credits or outright refunds.
Often when considering what type of SLA a platform can provide, there is a tendency to forget to consider some of the components of the system. If the SLA isn’t carefully considered, it can quickly become very difficult and expensive to meet [Source].
Example: Your company would like to offer a 99.9% SLA on your entire platform. Consider the following services that are required for your service to operate normally:
- Email service provider: 99.9%
- DNS provider: 99.99%
- Authentication service provider: 99.9%
- AWS services: 99.9%
- Twitter feed: 99%
Write an SLA for your platform that breaks down acceptable amounts of downtime for your application and for third-party services separately. Also, define periods of excused downtime and caveats for reduced functionality of non-critical components.

Resources:
Recovery Time Objectives (RTO)
The maximum duration of a service interruption and you agree to this time in your SLA.

- RTO is calulated like uptime on a monthly bases.



Recovery Point Objective (RPO)
It’s the maximum amount of time over which we can lose data.
The AWS solution for RPO are as follows
- Redundancy
- Versioning e.g S3 version bucket for the case of data corruption to undo/revert
- Point-in-Time recovey e.g. with RDS or DynamoDB (for very small RPO)
It’s important to have strong monitoring and alerting.


In time of happening an incident, if the whole system is getting down together, the RPO is zero. Because we lost no data.
RDS database
- Creating a RDS database with backup enabled to prevent high RPO.
- In creating steps this checkbox is important to point-in-time recovery.
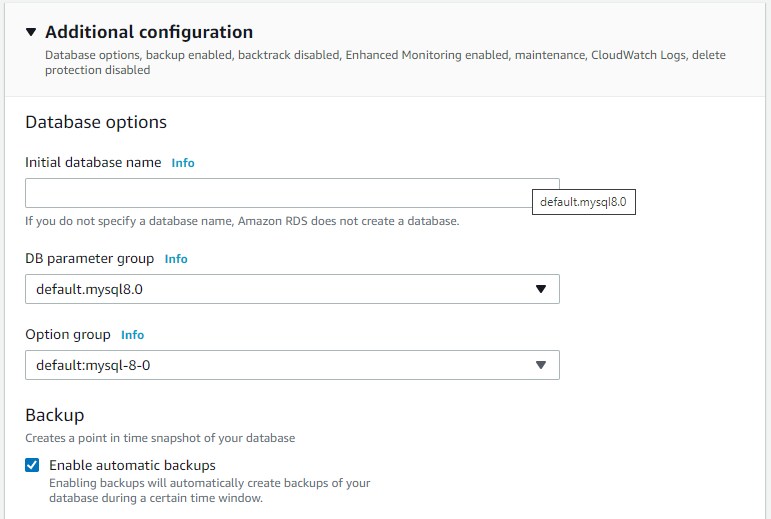
- After creating the RDS database, then we can execute a point in time recovery.

- Restore point can be latest or custom
- The the name of restored instance must be specified

- Then we will have the original and the restored instance

Disaster Recovery
- is about how fast we can restore services after major failure
- RPO and RTO is applyed to any incident (consider the worst-case scenario)
RTO and RPO numbers apply to localized outages, but when setting your RTO and RPO, you must take into account worst case scenarios. The term Disaster Recover is used to describe a more widespread failure. In AWS, if you normally run your services in one region, a large enough failure to make you move your system to another region would be a Disaster Recovery (DR) event [Source].
Disaster Recovery usually involves the wholesale moving of your platform from one place to another. Outside of AWS, you might have to move to a backup data center. Inside AWS, you can move to a different region. Disaster recovery is not something you can do after an incident occurs to take down your primary region. If you have not prepared in advance, you will have no choice but to wait for that region to recover. To be prepared ahead of time, consider all of the things you will need to restart your platform in a new home. What saved state do you need, what application software, what configuration information. Even your documentation cannot live solely in your primary region. All of these things must be considered ahead of time and replicated to your DR region [Source].
Which tools have help us in DR on AWS
Geographic Recovery / Multi-region Services (typical DR plan calls for re-establishing your platform)
| AWS Service | Multi Region capability |
|---|---|
| DynamoDB | – Active/Active replica via Global Table |
| S3 | – Active/Passive replica + Double costs for replica |
| IAM | – By default Global |
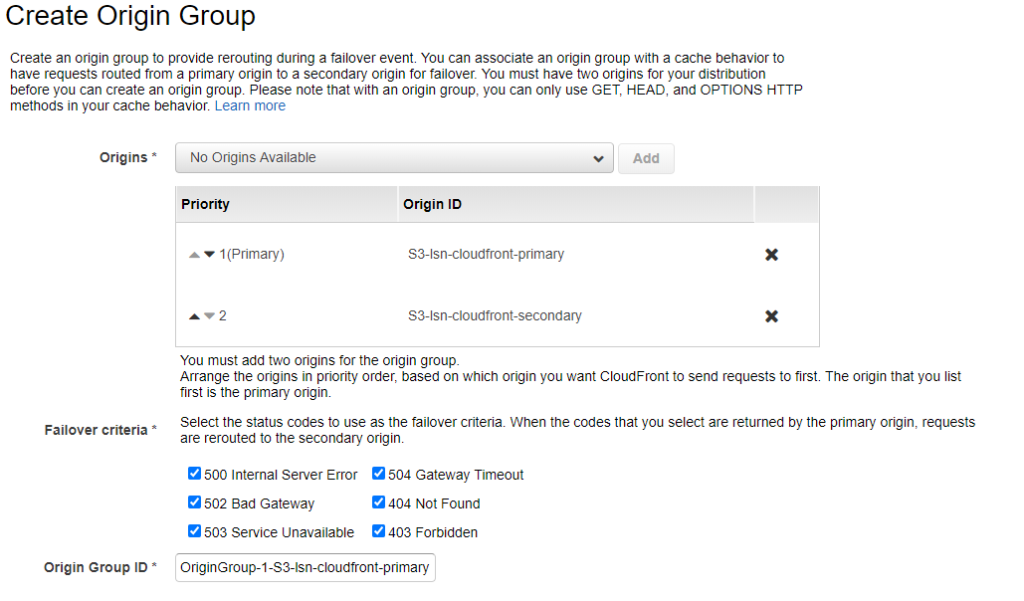
| CloudFront | – Active/Passive replica via Origin Group, failover/failback automatically |
| RDS | – Active/Passive replica, failover/failback manually |


CloudFront
AWS CloudFront is a content distribution network. It allows for edge location spread around the world to cache content so that the original source only needs to be consulted after a certain amount of time has expired. CloudFront is a global AWS service and has the ability to serve files from an S3 bucket. It also can be configured to have a primary bucket and a backup bucket in case the primary is not available.
Step1

Step2

Step3

Step4

One thought on “AWS : Business Objectives”