We should ask this questions ourselves by architecting a solution by designing its monitoring solution
how would you diagnose issues with an application
how would you understand it’s health
what are it’s choke points
how would you identify them and what would you do when something breaks
Like the firefighting maneuver that must be executed half-yearly or yearly in each company, we have to use “chaos engineering” technique to intentionally cause breakage in the environments in a controlled manner to test monitoring, alerts, react of the architecture and resiliency of our solution.
Decide for the right resource and architecture for youe product
Choose the appropriate architecture based on your requirements
Know which compute options is right for your workload
Identify the right storage solution that meets your needs
Decide how you’re going to manage all your resources
Automation: The use of software to create repeatable instructions and processes to replace or reduce human interaction with IT systems
Cloud Governance: The people, process, and technology associated with your cloud infrastructure, security, and operations. It involves a framework with a set of policies and standard practices
Infrastructure as Code: The process of managing and provisioning computer resources through human and machine-readable definition files, rather than physical hardware configuration or interactive configuration tools like the AWS console
IT Audit: The examination and evaluation of an organization’s information technology infrastructure, policies and operations
CloudFormation
CloudFormation is a AWS service for create infrastructure as code.
it’s a yaml file
How to start with CloudFormation
Services -> CloudFormation
Create stack “With new resources (standard)”
Template is ready
Upload a template file
Click “Choose file” button
Select provided YAML file
Next
CloudFormation Template sections
Format version
Decsription
Parameters
Resources
Outputs
Each AWS Account has its own AWS Identity & Access Management (IAM) Service.
If you know Azure On Microsoft Azure, we have a Subscription. The AWS Account can be equivalent to the Azure Subscription. With a difference. Each AWS Account can have its own IAM Users but in Azure, we have a central IAM Service, called Azure Active Directory (AAD). Each above-called service is a huge topic but we don’t do a deep dive right now.
The AWS IAM User can be used
Only for CLI purposes. This user can’t log in to the AWS Portal.
Only for working with the AWS Portal. This user can’t be used for CLI.
Both purposes. This user can be used to log in to the AWS Portal and CLI.
Pipeline User
The first question is why do we need a Pipeline User?
Automated deployment (CI/CD) pipeline and prevent manual or per-click deployment.
We can only grant the pipeline user for some specific permissions and audit the logs of this user.
This user can work with AWS Services only via CLI. Therefore it has an Access Key ID and a Key Secret.
If you know Azure It’s used like a Service Principal, that you have a client-id and client-secret.
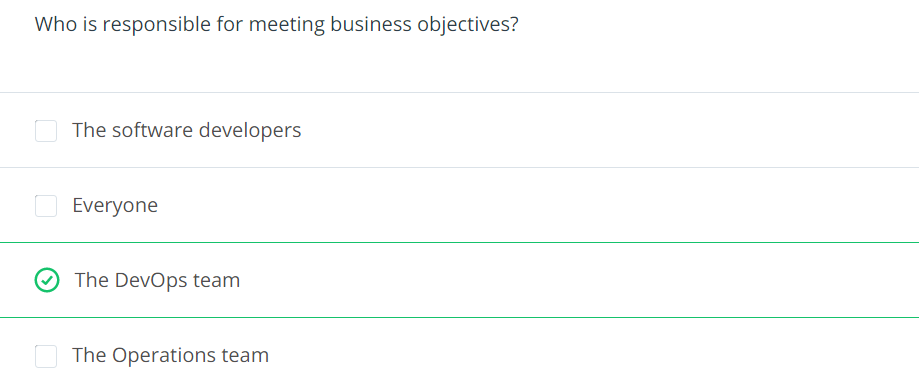
Business Objectives define how the business can market and sell its products and services. It is crucial for all parts of the business to agree and strive for the same business objectives in order to smoothly operate the business and work with customers.
Key concepts
Uptime:
Downtime
Recovery Time Objective (RTO): maximum amount of time that your service would be down.
Recovery Point Objective (RPO): maximum amount of time over which you would lose data.
Disaster Recovery: Bringing our system (major service) in another place in case of complete region outage.
They are the commitment that we do with customers
Big picture
Business objectives are where the other business functions of your company meet with the Engineering function. These other areas of the company focus on signing customers, managing finances, supporting customers, advertising your products, etc. Where all of these teams meet is in the realm of contracts, commitments and uptime. This is where other parts of a business have to collaborate with Engineering in order to come up with common goals and common language.
Developing your intuition
Develop regular communication: when working across departments within your business, it’s important to communicate regularly and clearly.
Be on the same page: using the same language is a good way to make sure that all teams are on the same page.
Push back where necessary: It’s imprerative to be well-prepared when dealing with business objectives. Other business units might wish to make more aggressive commitments to close more sales. Be cautious and transparent. Make sure that business understands what meeting higher commitments will cost in term of both time and dollers.
Be Prepared: Service disruptions can be rare enough that how to recover can be forgotten and can be tricky. Practicing recovery operations in key to doing them well. Which in turn is key to keep relationship and solid footing with your peers in other parts of the business.
It is important to gauge how much effort and cost will be involved in meeting different business objectives. Communicating these numbers will help keep the whole company centered around common and achievable goals. Setting unrealistic or unachievable goals can quickly lead to poor morale and missed deadlines. Before committing to a business objective, ensure that you have an idea of how to build, run, monitor and maintain a system that can achieve the desired metrics, and make sure that the rest of the business understands the resource that will be required to do so. In this fashion, it is key to get all parts of the company to work together to set these goals. These goals are so critical to success and potentially costly to achieve that they often must be set at the highest levels of the company.
Uptime
Percentage of time: the percentage of time that a service is available. 99,9% is a standard uptime by many service level agreements. This percentage is measured over the course of a month.
Part of every Service Level Agreement: if you likely face penalties for the SLA, it comes usually in the form of monetary or service credit that you would owe your customers.
Requires diligence: you need to tack your platform uptimes to demonstrate to your customers that you are measuring it and meeting commitments.
In order to maintain a high level of uptime, we must have redundancy throughout the services. Everything must be redundant: – Databases – Networking – Servers – Staff
Uptime is a measure of how much time an application or service is available and running normally. Uptime is often measured as a percentage, usually in the “number of 9s” vernacular. For example, “4 9s” refers to a service being available for 99.99% of a time period.
Services that offer Service Level Agreements (SLAs) typically start at 99% and get more stringent from there. 99.9% is a common SLA. The more “9s” an SLA offers, the more difficult and costly it is to achieve. You must ask yourself how much effort you are willing to put in and how much your company is willing to pay before proceeding into the territory of 4 9s or beyond.
Allowed downtime is calculated on monthly bases because some months have different length.
Allowed downtime = (30 days 24 hours 60 minutes) – (30 days 24 hours 60 minutes * SLA percentage)
For example a 99% = 7.3 hours of allowed downrime per month
Drafting a Service Level Agreement (SLA)
When drafting a Service Level Agreement (SLA) for your platform, there are many things to consider. You will need to ponder what you will need to implement in order to meet the SLA, and also understand what types of guarantees that you are providing to your customers that you will meet the SLA. Monetary compensation is common for SLA violations either in the form of service credits or outright refunds.
Often when considering what type of SLA a platform can provide, there is a tendency to forget to consider some of the components of the system. If the SLA isn’t carefully considered, it can quickly become very difficult and expensive to meet [Source].
Example: Your company would like to offer a 99.9% SLA on your entire platform. Consider the following services that are required for your service to operate normally:
Email service provider: 99.9%
DNS provider: 99.99%
Authentication service provider: 99.9%
AWS services: 99.9%
Twitter feed: 99%
Write an SLA for your platform that breaks down acceptable amounts of downtime for your application and for third-party services separately. Also, define periods of excused downtime and caveats for reduced functionality of non-critical components.
In time of happening an incident, if the whole system is getting down together, the RPO is zero. Because we lost no data.
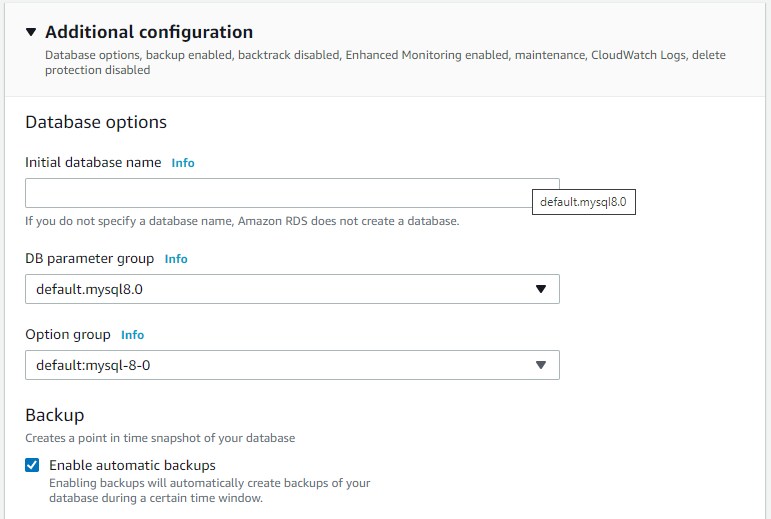
RDS database
Creating a RDS database with backup enabled to prevent high RPO.
In creating steps this checkbox is important to point-in-time recovery.
After creating the RDS database, then we can execute a point in time recovery.
Restore point can be latest or custom
The the name of restored instance must be specified
Then we will have the original and the restored instance
Disaster Recovery
is about how fast we can restore services after major failure
RPO and RTO is applyed to any incident (consider the worst-case scenario)
RTO and RPO numbers apply to localized outages, but when setting your RTO and RPO, you must take into account worst case scenarios. The term Disaster Recover is used to describe a more widespread failure. In AWS, if you normally run your services in one region, a large enough failure to make you move your system to another region would be a Disaster Recovery (DR) event [Source].
Disaster Recovery usually involves the wholesale moving of your platform from one place to another. Outside of AWS, you might have to move to a backup data center. Inside AWS, you can move to a different region. Disaster recovery is not something you can do after an incident occurs to take down your primary region. If you have not prepared in advance, you will have no choice but to wait for that region to recover. To be prepared ahead of time, consider all of the things you will need to restart your platform in a new home. What saved state do you need, what application software, what configuration information. Even your documentation cannot live solely in your primary region. All of these things must be considered ahead of time and replicated to your DR region [Source].
Which tools have help us in DR on AWS
Geographic Recovery / Multi-region Services (typical DR plan calls for re-establishing your platform)
AWS Service
Multi Region capability
DynamoDB
– Active/Active replica via Global Table
S3
– Active/Passive replica + Double costs for replica
IAM
– By default Global
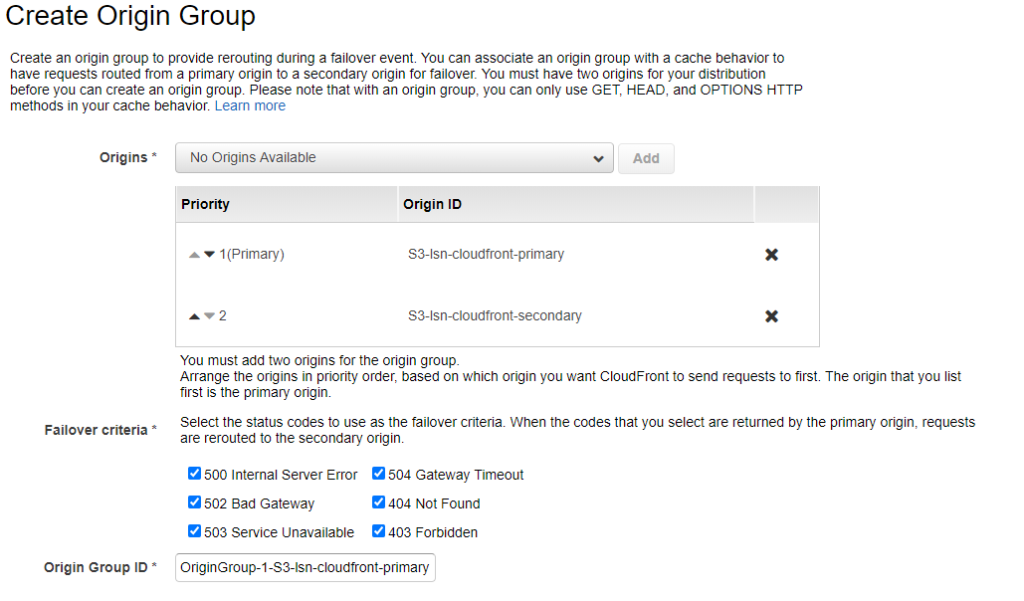
CloudFront
– Active/Passive replica via Origin Group, failover/failback automatically
AWS CloudFront is a content distribution network. It allows for edge location spread around the world to cache content so that the original source only needs to be consulted after a certain amount of time has expired. CloudFront is a global AWS service and has the ability to serve files from an S3 bucket. It also can be configured to have a primary bucket and a backup bucket in case the primary is not available.
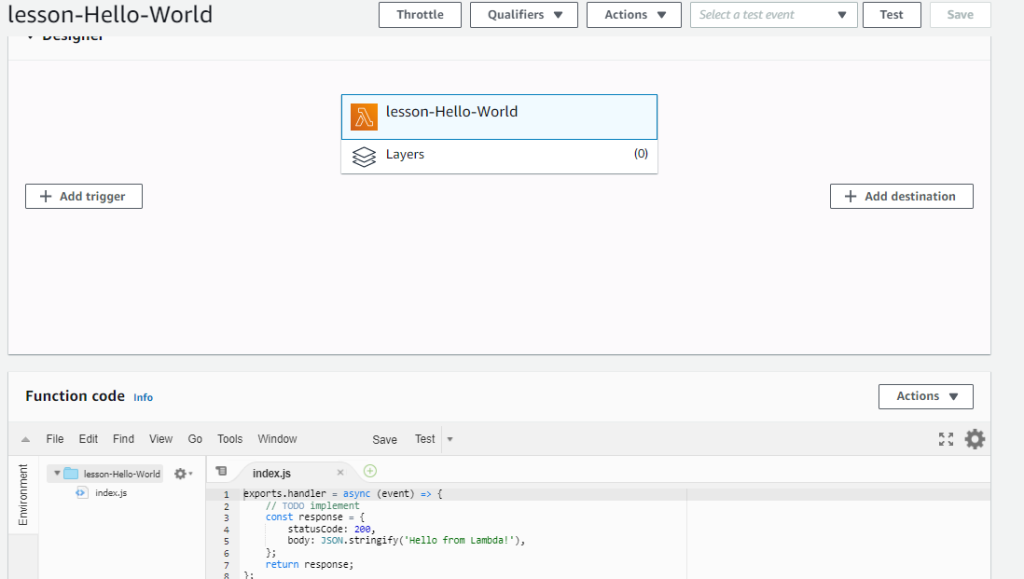
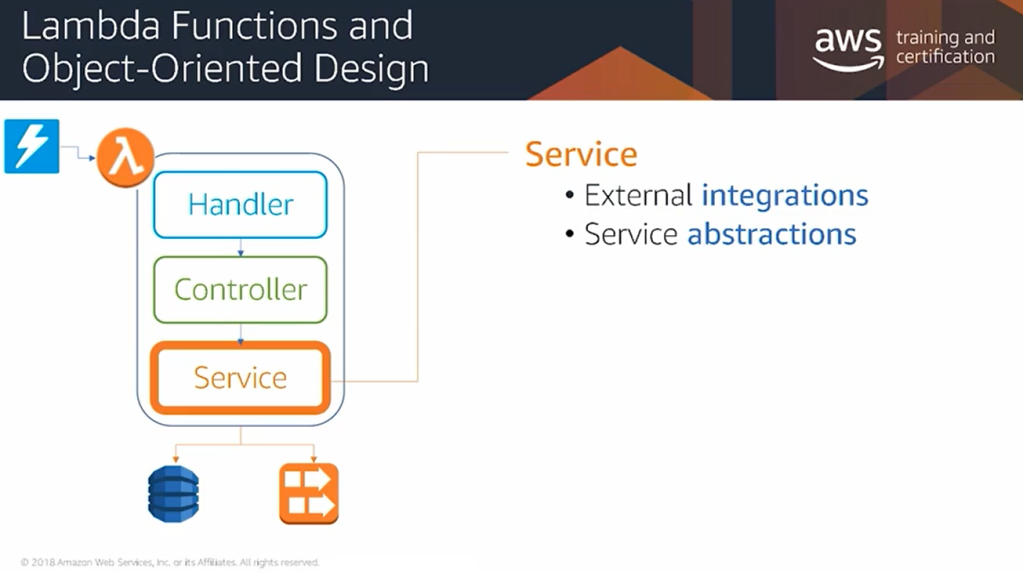
AWS Lambda is one of the Serverless possibilites, We can bring our code and have it run in response to an event.
Handler is the primary entry point and the whole code can follow the OOP standards.
Lambda function and object oriented design
This is the usual layer of the lambda function. The business logic must not be developed in handler.
The business logic must be developed in controller class.
Services is for interfaces with external services.
when a Lambda function runs, each time a new execution context is created, there’s a bootstrap component to that start up time for that function where the runtime itself needs to be bootstrapped, and all of the dependencies for that function have to be loaded from S3 and initialized. In order to optimize the cold starts for your function, you should consider reducing the overall size of your libraries.
So that means removing any unnecessary dependencies in your dependency graph, as well as being conscious of the overall start up time for the libraries you’re using. Certain libraries like Spring within the Java context take a long time to initialize, and that time is going to impact the cold start times for your function. Also, if you’re using any compiled libraries within your function, consider statically linking them instead of using dynamic link libraries.
Amazon DynamoDB is a fast NoSQL database service for all applications that need consistent, single-millisecond latency at any scale. It is a fully managed database and supports both document and key-value data models. Its flexible data model and reliable performance make it a great fit for mobile, web, gaming, ad-tech, IoT, and many other applications. [Source]
Create DynamoDB
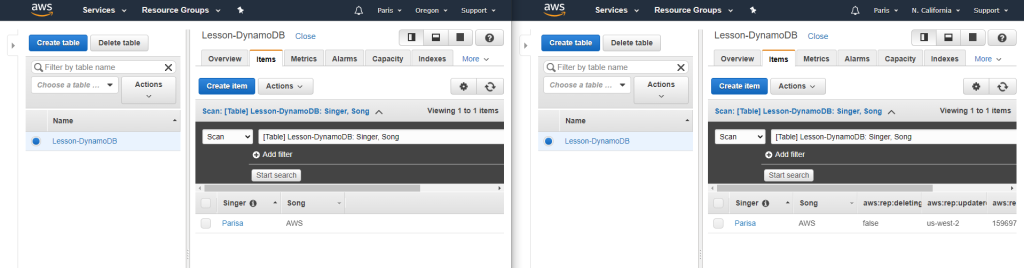
Create Global table
For creating Global table, the DynamoDb Stream must be enabled. The following figure demonstrates how to enable it.
Then we use the Global Tables tab and Add region.
After I added a new item to “Oregon” table, the values would be added to the “California” as well.
To have a resilience platform all parts must be configured to befault tolerant. But first the level of redundancy and resilienc must be determined.
Fault Tolerant Server-based Services
Server bases services are those that are “instance” based. Services like RDS and ElastiCache are instanced based in that you can run one instance, but you will not have any fault tolerance. In order to gain high availability, you need to tell the service to provision a second instance for the primary instance to failover to, should there be an issue with it.
This model is similar to traditional data center environments. A good way to tell if a service is a server/instance based service or if the service is a pre-existing product that AWS has created a service with (MongoDB, Redis, MySQL, Postgres).
Most of the server based services have similar concepts for handling a hardware failover automatically. This functionality is the same that handles a single availability zone failure. By creating active/standby pairs of servers that replicate and by having each member of the pair in a different availability zone, you create the infrastructure that handles both of these failure modes.
ElastiCache
ElastiCache is one of these services. You will create an ElastiCache cluster that does not have a single point of failure, and that can handle an AZ outage.
First, create an ElastiCache subnet group in the default VPC using each available subnet and
then create a multi-AZ redis cluster.
Elasticache’s Subnet Groups
AWS > Elasticache page > Subnet Groups
The Subnet Groups option is availble on the service page
Then create a new Subnet Groups. Based on the region of the selected VPC the Availability Zone is listed.
We can have only one subnet in each availability zone. See the figure above, I tried to add more but it’s not possible.
As next we create the Redis Cluster. The created Subnet in the previous step, is selected in Subnet Groups.
DynamoDB
DynamoDB is a native AWS service for non-relational databases
It is Multi-AZ by default and can be made Multi-Region with DynamoDB Streams and by creating a Global DynamoDB table
Global table is multi-region and active/active (it means any changes to one table is propagated to sll other tables)
DynamoDB scales to extremely high loads with very fast response times
It also supports configuring a caching layer in front of the database.
DynamoDB Streams allow every change made to a DynamoDB table to be “streamed” into other services. These other services can then choose what actions to take on the different items or operations within the stream.
In DynamoDb each database cintains just one table
This table has just one primary key and optional sort keyby default
It’s possible to have multi primary key, sort key on the table.
Indeces as well
charge is based on operation in seconds
or pay on demand
Automatic scale up and down
DynamoDB Streams And Global Tables
DynamoDB Streams capture all changes made to a DynamoDB Table. This includes only actions that modify the table, not actions that only read from the table.
DynamoDB Global Tables take advantage of DynamoDB Streams the create Multi-Region active/active DynamoDB Tables. This allows you to modify a table in multiple regions and have those changes reflected in all regions.
Multi-Region, active/active data stores are a big deal and extremely useful for use cases that require it.
DynamoDB is a non-relational database. It is a fully managed service created by AWS. With DynamoDB you create tables, but unlike a relational database, each table is completely independent.
DynamoDB is not like the server-based services that AWS offers (RDS, ElastiCache, etc.), it is “serverless” in the sense that you do not have any control over the physical infrastructure that it runs on. You do not pay for the service when you are not using it (except used storage space). Because DynamoDB is different than server-based offerings, the mechanisms for redundancy are also different. DynamoDB offers multi-region, active/active service if you elect it. This is called DyanmoDB Global Tables.
Amazon DynamoDB is a fast NoSQL database service for all applications that need consistent, single-millisecond latency at any scale. It is a fully managed database and supports both document and key-value data models. Its flexible data model and reliable performance make it a great fit for mobile, web, gaming, ad-tech, IoT, and many other applications. [Source]
Fault Tolerant Operations
1- Subnet Groups
To get Multi-AZ availability, you need to configure a Subnet Group (contains subnets in different AZs) within the service. A subnet is attached to an AZ, and creating a grouping of subnets within the service and tells the service where it can place the primary and standby instances of a service.
Based on the service and data volumne, creating a new instance in secondary subnet, can takes diffrent duration.
2- Multiple instances
To reduce downtime to seconds, multi instances have to be created.
3- Multi-AZ checkbox
4- Multi Region Redundancy
Subnet Groups are key to creating Multi-AZ redundancy in server-based services. Subnet Groups define the different availability zones that your service will run in, and having multiple instances allow for fast failover if a single AZ were to go down.
Multi-Region redundancy is more tricky. Depending on the service, it is harder, or not possible to run a service with failover between regions.
Some services allow to have read replica in a second region, but later you have to activate it as primary e.g. Amazon RDS.
Some services don’t have multi region support e.g. Elastic Search.
Select region for vnet and regions are region/zone because we have for example East US & East US 2
Select region for VPC
Subnet is created in vnet’s region.
Subnet is created in different zones of the region
GCP
coming soon..
Multi-cloud : Public IP
Azure
AWS
GCP
Static IP
Elastic IP
Dynamic IP
Multi-cloud
You can configure VPN between cloud providers (it’s straight forward) and it’s the same as VPN between on-prem and cloud with setting up the Gateway and then we have an encrypted tunnel for the traffic between cloud providers.
Azure, GCP, and AWS support IKEv2 in virtual private network
Regions and Availability Zones allow anyone to create worldwide infrastructure with ease. They also allow for many options for creating redundancy within your platform. By properly using these components, you can create world-class level systems in terms of both scale and reach.
A Virtual Private Cloud (VPC) is a isolated private network that you control within the larger AWS network. These private networks allow you to configure your network architecture the way you desire. A VPC is region specific. You decide if your VPCs connect to each other or if you keep them independent. If you connect your VPCs, it’s up to you to configure them according to regular networking guidelines.
VPC aspects
Security groups are the same as firewall but not exactly
Two VPCs can have peering, even if they are in different regions
One VPC per region has automatically multi-AZ
AWS create a default VPC in every region but can be deleted
Services in VPC
The instance oriented fetures
Amazon RDS
Elastic cache
Document DB
Elastic search
EC2
Load balancer
Net Tune
Services not in VPC
Service oriented features and global services that have access to internet
SQS
S3
DymoDb
SNS
Cloud front
SCS
API gateway
Network Ranges
A network range is a consecutive set of IP addresses.
Network ranges are described using “CIDR” notation. CIDR notation consists of the first IP address of the network range, followed by a “slash”, followed by a number. That number describes how many consecutive address are in the range. A “/24” address has 255 addresses, while a “/16” has 65,536 addresses.
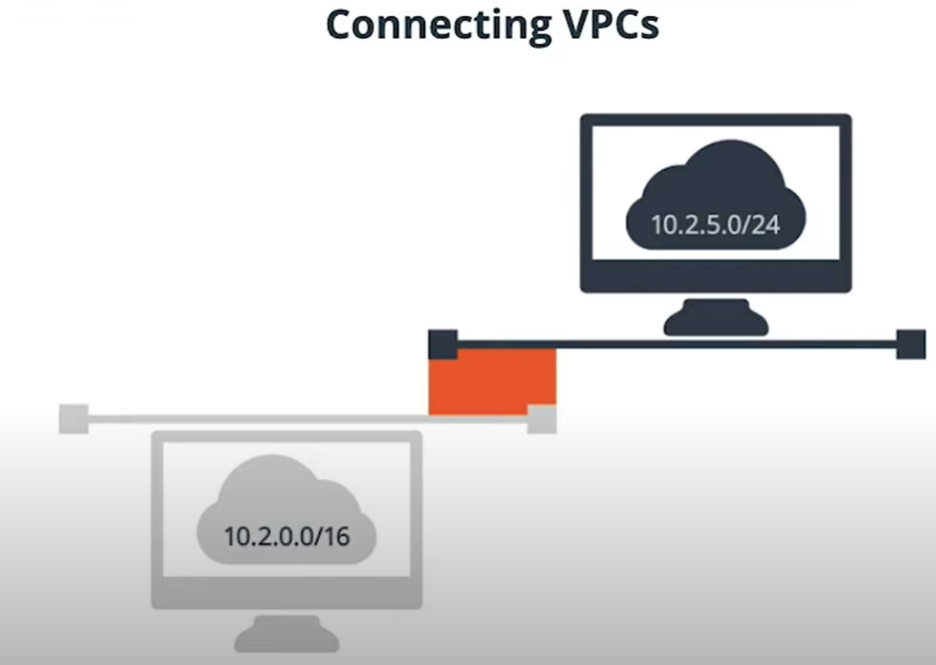
We cannot connect two VPCs with overlapping IP address ranges
Create VPCs
There are two ways in the AWS management console to create a new VPC.
You can create a very basic VPC by creating a new VPC from within the “Your VPCs” section of the VPC service. This option is best if you are an advanced VPC user and want to customize your VPC completely.
the second way is by using the VPC launch wizard.
Using the “Launch VPC Wizard,” create a new VPC. Select the “VPC with a Single Public Subnet” option. Name the VPC “Lesson-VPC” and keep the default options and create the VPC.
Review the new VPC, the routing tables that were created with it as well as the subnet and Internet Gateway.
Step1: create VPC
Step2: VPC created
VPCs List The ‘Lesson-VPC’ is my new VPC
Step3: Create subnet
The subnets can be created in any availability zones of the VPC’s region.
Network components
Component
Description
Subnets
is tied to Availability Zone (AZ) and all resources created in this subnet are located in this availability zone
Route tables
is attached to one or more subnets and can be shared between subnets in different AZ.
DNS
DHCP
IPv4/6
Internet Gateway (Network routing)
is represented in Route Table of the subnet and the services created in the subnet can send traffic to internet with public IP. Internet can send traffic to instances as well.
NAT Gateways (Network routing)
Services can send traffic out to internet but cannot receive from internet.
Security Group
is a statefull firewall, can attach to EC2, RDS database
Network ACLs
Network Address Control List, is a kind of stateless firewall and is applied to subnet.
Network routing
Options
Description
Internet Gateways
NAT Gateways
No internet connections
is for connecting two subnets in a VPC with each other
VPN connections
encrypted connection to connect to on-prem
DirectConnection
datacenter to AWS
Debugging VPC Network
VPC Flow Logs
Flow logs allow you to see higher level network debugging information like the source port and source IP, and destination port and destination IP of traffic flowing within your VPC.
Traffic Mirroring
Traffic mirroring is like traditional “packet sniffing” on specific ports.
Edge cases
Multicast networking : is not supported in AWS
Penetration testing
Running email server
AWS networking does have some limitations that your own data center network would not.
You cannot use multicast in a VPC
You cannot put network cards into “promiscuous” mode to sniff ethernet packets.
There are some restrictions on opening up ports for SMTP
You cannot have network scans run against your account without discussing with AWS
Hybrid, multi-cloud management platform for APIs across all environments. Nowadays, enterprises are API producer and they expose their services to their customers via APIs.
With Azure API Management Service enterprises can selectively expose their services to their partners, consumers in a secure manner.
Enterprise level benefits of Azure API Management
Exposing the services/APIs in a secure manner.
A Framework for API Management can be approved by compliance gate and teams can use it without repeating the same compliance gate process.
A list of exposed APIs/Services are always for monitoring available for CTO.
Must haves at enterprise level implementation for Azure API Management :
Define a secure framework for API Management
On-board teams to be able to use this framework
Support and monitor the Teams activities
Enterprise Level limitation
If an enterprise level decides to use the custom role assignment must pay attention to 2000 RBAC assignment per subscription.
Framework for Azure API Management
In the framework document we must define at least two teams and the functional and non-functional requirement must be clarified and explained in great detail.
Service Provider Team : is the team who define the framework and perform the compliance gate process for the service, they want to provide
Consumer Team : uses the provided service, because
They need this service in their solution.
They receive an On-Boarding and start technically easier with this service.
They can use the support of this service instead of using their resources
They don’t need compliance gate process for this service
Functional requirements
Non-functional requirements
By which cloud provider?
How teams can request this service?
Is it private or public cloud?
How they can get on-boarding?
How can have access to resources?
How they can get support?
How to determine the dev/QA/prod environments?
How are the SLA?
How team can access his resources?
What are the service provider team’s responsibilities?
How they can add/remove/config their resources?
What are the consumer team’s responsibilities?
Is their any automated flow? if yes, what are they?
How the automated flow can be considered in CI/CD? (if necessary for consumer team)
Most organizations choose to work with multiple cloud providers, because it’s a struggle for an enterprise to find only one public cloud infrustructure provider, which meet all their requirements. [refrence]
The following figure demonstrates that the multi-cloud solution is a sub concept for hybrid-cloud computing.
Multi-cloud solutions are sub topic of the hybrid-cloud computing.
Multi-cloud scenarios
1-Strategic advantages of partitioned complexity
To avoid committing to a single vendor, you spread applications across multiple cloud providers. Best Practice:weight the strategic advantages of a partitioned complexity this setup brings. Achieving workload portability and consistent tooling across multiple cloud environments increases development, testing, and operations work. [1]
2-For regulatory reasons
For regulatory reasons, you serve a certain segment of your user base and data from a country where a vendor does not yet have any presence. Best Practice:Use a multi-cloud environment only for mission-critical workloads or if, for legal or regulatory reasons, a single public cloud environment cannot accommodate the workloads. [1]
3-Choose the best services that the providers offer
For deploying application across multiple cloud providers in a way that allows you to choose among the best services that the providers offer. Best practice:Minimize dependencies between systems are running in different public cloud environments, particularly when communication is handled synchronously. These dependencies can slow performance and decrease overall availability. [1]
4-To have data autonomy
To have data autonomy in the future, therefore companies can take their data with them wherever they end up going.
Advantage of multi-cloud scenarios
To avoid vendor lock-in. The multi-cloud helps lower strategic risk and provides you with the flexibility to change plans or partnerships later. [1]
If the workload has been kept portable, you can optimize your operations by shifting workloads between computing environments. [1]
Hybrid-cloud scenarios
Hybrid-cloud description by National Institute of Standards
Hybrid cloud is a composition of two or more distinct cloud infrastructures (private, community, or public) that remain unique entities, but are bound together by standardized or proprietary technology that enables data and application portability. [2]
Cloud and on-premises, which were previously distinct entities and had cumbersome interaction configuration, are now converging to provide more efficient, less costly, and more flexible operation model for workflows.
1-Backup & Archive [2]
2-Data Protection [2]
3-Lifecycle Partitioning [4]
Lifecycle partitioning is the process of moving parts of the application development lifecycle to the cloud while the rest remains on premises. The most popular is the cloud deployment and testing but move to on-premises for the production deployment.
4-Application Partitioning [4]
A part of an application is running in the could and the other part runs on premises. For example, Sony PlayStation runs databases for individual games in the cloud but takes care of user authentication on-premises.
5-Application spanning [3]
Application spanning happens when the same application runs on-premises and in the cloud. “Best Buy” is an example of the application spanning. The entire online store application is running across multiple cloud regions and multiple on-premises data center to allow it to quickly adjust to demand.